実際に動かしてみないとよくわからないので、遅ればせながらAmazon EC2をさわってみた。
まずは、何はなくともAWS (Amazon Web Services)のアカウントを作る。そして、X.509証明書も作っておく。
EC2を簡便に利用するためにElasticfoxというFireboxプラグインが存在することは知っていたけど、このためだけにFirefoxを使うのもなぁと思っていたら、最近はAmazon Management Consoleというサービスがあるようだ。両者の違いはわからないけど、AMI(Amazon Machine Image)の検索から、インスタンスのライフタイム管理、Elastic IPなどの設定など、必要そうな機能はそろってそうだ。
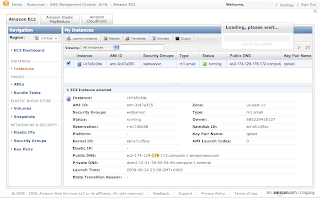
Amazon Management Consoleにサインインすると、ダッシュボードが表示されるので、さっそくAMIを探す。コミュニティで作られたAMIは2630個もあってとても選んでられないので、とりあえずQuick StartにあるFedora 8を選択し、インスタンスを起動する。すると、まずAMIにSSHログインするために必要なキーペアを作ることになる。ここでプライベートキーがダウンロードされるんだけど、なぜか下のスクリーンショットのように、「Loading, please wait...」のダイアログが消えずに残ったままになっている。ぜんぜん終わらないなと、しばらく待惚けしてしまった。
あとはファイアウォールの設定をするとインスタンスが起動する。Consoleのステータスを見る限り、インスタンスの起動に50秒、終了に30秒ぐらいかかっているようだった。
さて、さきほどダウンロードしたキーペアを利用して、sshログインしてみる。
$ chmod 400 qstest.pem
$ ssh -i qstest.pem root@ec2-174-129-178-172.compute-1.amazonaws.com
__| __|_ ) Fedora 8
_| ( / 32-bit
___|\___|___|
Welcome to an EC2 Public Image
:-)
Getting Started
--[ see /etc/ec2/release-notes ]--
[root@domU-12-31-39-00-54-94 ~]# uname -a
Linux domU-12-31-39-00-54-94 2.6.21.7-2.fc8xen #1 SMP Fri Feb 15 12:39:36 EST 2008 i686 athlon i386 GNU/Linux
インスタンスはスモール(1時間0.10 USD)を選択したが、CPUは低消費電力版AMD Opteron 2.6GHz(と/proc/cpuinfoでは見えるが、Xenによって1.0から1.2 GHz相当に制限がかかっているかもしれない。コアあたり2個ぐらいインスタンスがわりあてられるとか)、メモリは1.7GBになる。日本とのRTTは200ミリ秒程度。
[root@domU-12-31-39-00-54-94 ~]# cat /proc/cpuinfo
processor : 0
vendor_id : AuthenticAMD
cpu family : 15
model : 65
model name : Dual-Core AMD Opteron(tm) Processor 2218 HE
stepping : 3
cpu MHz : 2599.998
cache size : 1024 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu tsc msr pae mce cx8 apic mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt rdtscp lm 3dnowext 3dnow up pni cx16 lahf_lm cmp_legacy svm extapic cr8legacy ts fid vid ttp tm stc
bogomips : 6502.82
clflush size : 64
[root@domU-12-31-39-00-54-94 ~]# cat /proc/meminfo
MemTotal: 1747764 kB
MemFree: 1446716 kB
Buffers: 217076 kB
Cached: 33748 kB
SwapCached: 0 kB
Active: 23096 kB
Inactive: 234136 kB
HighTotal: 1003528 kB
HighFree: 953652 kB
LowTotal: 744236 kB
LowFree: 493064 kB
SwapTotal: 917496 kB
SwapFree: 917496 kB
Dirty: 40 kB
Writeback: 0 kB
AnonPages: 6416 kB
Mapped: 5616 kB
Slab: 8912 kB
SReclaimable: 4568 kB
SUnreclaim: 4344 kB
PageTables: 960 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
CommitLimit: 1791376 kB
Committed_AS: 42364 kB
VmallocTotal: 114680 kB
VmallocUsed: 1360 kB
VmallocChunk: 112936 kB
さて、sshログインに必要な設定
(/root/.ssh以下のパブリックキーおよびauthorized_keys)は、/etc/rc.localから呼ばれるシェルスクリプト経由で実行される。あと、ec2-ami-tools RPMもインストールされる。この辺は自分でAMIを作るとしたら押さえておく必要があるな。
(追記)ちょっと勘違いしていた。シェルスクリプト(/usr/local/sbin/get-credentials.sh)は、sshでログインできるように、最初に作ったキーペアのパブリックキーをcurlでダウンロードしてきて、authorized_keysに書き込むという処理を行う。サーバ側はIP要求者のIPアドレスでも見て、どのキーペアを利用しているかをチェックしているのだろうか?
このあたりの挙動は「
Amazon EC2の機能を詳しく見てみる(3)--インスタンスデータとAMI」に詳しい。RESTインタフェースによってインスタンスのデータを取得できるとのこと。


